
L’infiniment puissante atomic research
A new way to organise UX knowledge
in an infinitely powerful manner.
Daniel Pidcock
Parfois aussi nommée atomic UX research, l’atomic research tire son nom de l’atomic design théorisé par Brad Frost. Il s’agit cependant de deux notions très différentes. L’atomic research est un système de gestion des connaissances de la recherche UX, alors que l’atomic design, est une méthodologie de conception d’interface.
D’abord théorisée par Tomer Sharon (anciennement Head of User Research & Metrics chez Goldman Sachs, WeWork et Google Search) et Daniel Pidcock, (le fondateur du logiciel de mise en forme de repository Glean.ly) l’atomic research est une approche qui redéfinit les unités de base de la connaissance UX en “atomes” (aussi appelés “nuggets”) taggés. Plus simplement, l’idée est de déstructurer le matériau brut récolté à l’occasion d’une recherche utilisateur afin d’avoir une vision d’ensemble et granulaire avant analyse.
La nature des tags varie. Ils correspondent à des catégories et sous catégories distinctes, des niveaux d’organisation différents. Ils peuvent être des données de classement (date, source, localisation, priorité), de mesure (amplitude, fréquence), des appréciations qualitatives (comme une émotion ressentie par un·e interviewé·e) ou encore des indications démographiques (âge, classe socio-professionnelle). Ils permettent en tout cas de classer et d’ordonner les items par similarité afin de les traiter et de les analyser.
L’atomic research décompose ainsi le matériau issu de la recherche en 4 éléments distincts, dont le nugget (c’est-à-dire la donnée brute), auquel s’ajoutent les contextes de recherche, les insights et les recommandations.
Les 4 piliers de l’atomic research
1. Le contexte de recherche
Les contextes de recherche sont les manières dont les données sont récoltées : entretiens, questionnaires, outils de metrics. Leur multiplication enrichit la recherche.
Exemple : Lors d’une mission d’amélioration d’une application, on organise des tests avec des utilisateur·rice·s. Ces tests sont un contexte de recherche.
2. La donnée brute
En UX, on parle des nuggets au sens premier de pépites, d’items, de petites unités d’informations très précieuses. Un nugget n’est pas forcément textuel. Il peut être une observation autant qu’avoir un format chiffré (une statistique par exemple). Par contre, la donnée doit être unique pour rester atomic, elle ne contient qu’une information.
Exemple : Lors d’un test organisé avec un utilisateur sur une application, celui-ci ne trouve pas la barre de recherche. Le verbatim ou l’extrait correspondant de cet entretien (vidéo, enregistrement audio ou encore compte-rendu écrit) qui stipule que “l’utilisateur ne trouve pas la barre de recherche” est la donnée brute, le nugget. Une statistique récoltée par un outil de mesure (comme “50% des utilisateur·rice·s ne trouvent pas la barre de recherche”) est également un nugget.
3. Insights
Un insight est une hypothèse appuyée par un ou plusieurs nuggets. Ils peuvent être positifs, négatifs ou neutres. Ils n’aboutissent pas nécessairement sur une recommandation.
Exemple : Les utilisateur·rices ont dû effectuer les tests en ligne. Cela leur a déplu car leur environnement était un bureau partagé et qu’il y a eu beaucoup d’interruptions. L’insight est que “le bureau partagé n’est pas propice” et s’appuie sur des nuggets tels que “50% des utilisateur·rice·s ont été interrompu·e·s au moins une fois.” Cet insight ne servira pas forcément de base à une recommandation sur l’amélioration de l’application concernée. L’information demeure cependant intéressante pour l’organisation de tests futurs.
En revanche, “la barre de recherche est trop peu visible” est un insight dont on pourra tirer une recommandation en lien avec la mission, soit l’amélioration de l’application.
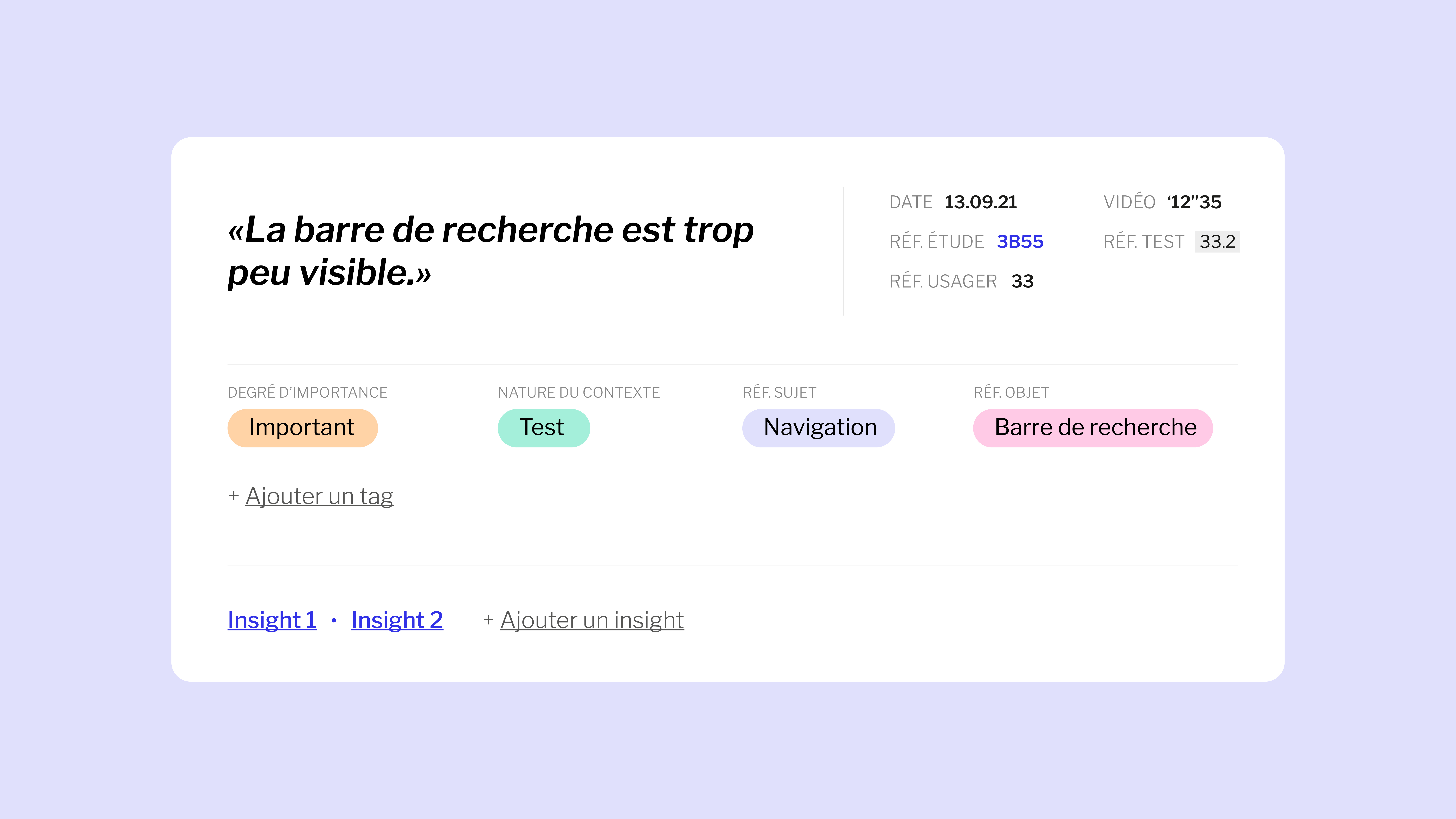
Un nugget rangé dans son repository, classé par tags
1 donnée brute = 1 nugget
4. Recommandations
Les recommandations sont des solutions proposées pour répondre à des insights. Un insight peut d’ailleurs engendrer plusieurs recommandations.
Exemple : Dans notre situation de mission d’amélioration d’une application, plusieurs recommandations pourraient être tirées de l’insight “la barre de recherche est trop peu visible” comme “mettre la barre de recherche au-dessus de la ligne de flottaison” ou encore “augmenter le contraste de la barre de recherche.”
À quels besoins l’atomic research répond-t-elle ?
L’atomic research est un archivage évolutif, vivant et dynamique. Les connaissances n’y sont pas rangées pour prendre la poussière mais bel et bien pour être retrouvées, partagées et exploitées. La base de données grandit ainsi au fur et à mesure des études, elle croît avec l’organisation.
L’atomic research résout essentiellement 4 problèmes rencontrés par les organisations qui font de la recherche.
1. L’éparpillement
Textes, enregistrements, tableurs, extraits… L’absence d’un code commun de classement, ainsi que la diversité des outils et des bases de données utilisés engendre un éparpillement dans lequel il est difficile (et décourageant !) de naviguer.
De plus, pour des raisons opérationnelles, les chercheur·se·s font aussi parfois leur propre tri dans leurs découvertes, afin que leurs rapports soient par exemple plus ciblés ou plus succincts. L’atomic research propose un système commun de navigation de l’ensemble des données de l’organisation.
2. L’oubli
Les connaissances acquises à travers les années tendent à partir avec leurs référent·e·s. Elles sont rarement documentées et classées pour pouvoir être retrouvées par quelqu’un d’autre. Pourtant, certains de ces apprentissages peuvent rester pertinents plus tard. Par exemple, ils peuvent être utilisés à des fins comparatives dans le temps. Ou encore pour illustrer une redondance dans les feedbacks issus de tests. Les évolutions de projets itératifs sont ainsi documentées.
Certaines données, si elles n’ont pas d’usage opérationnel au moment de la mission au sein de laquelle elles ont été trouvées, seront perdues. Ces informations “hors-sujet” sur le coup peuvent pourtant s’avérer utiles dans d’autres projets. L’atomic research, en collectant l’ensemble des informations, empêche l’oubli définitif de ces données.
3. La perte de temps
Dans les grandes organisations notamment, plusieurs pôles de production de connaissances peuvent exister sans être reliés. Les connaissances acquises ne sont pas forcément partagées entre tout le monde, ni organisées d’une manière qui les rendent accessibles et consultables par n’importe quel membre de l’organisation.
Des doublons peuvent voir le jour simplement parce qu’un pôle n’est pas au courant qu’un autre a déjà effectué cette recherche. L’atomic research prévient ce risque.
4. L’opacité
L’atomic research est avant tout un outil collaboratif. Elle se positionne en système de gestion des connaissances mais entraîne aussi une réflexion sur les processus de l’organisation en montrant une volonté de partage d’infos commun et relativement continu.
En proposant un thesaurus commun (repository) enrichi des découvertes de tou·te·s, l’atomic research offre une perspective de collectes de données plus ambitieuses sur un même sujet, car plus grandes et davantage entrecroisées. Elle est ainsi susceptible de produire des insights inédits.

Le repository est la base de données globales
1 ligne = 1 nugget